Amazon.com Inc.'s reputation as a reliable provider of cloud services took a hit on Monday when an outage lasting some 15 hours disrupted the operations of hundreds of companies, ranging from Apple Inc. to McDonald's Corp. to Epic Games Inc.
The incident, which some analysts are calling Amazon's worst outage since 2021, reminded the world of the perils of depending on a handful of cloud companies to deliver crucial computing and internet services. Outages like Monday's strike at a core premise of the cloud: that a centralized operation full of sharp engineers will keep servers running better and more efficiently than individual companies' own staff.
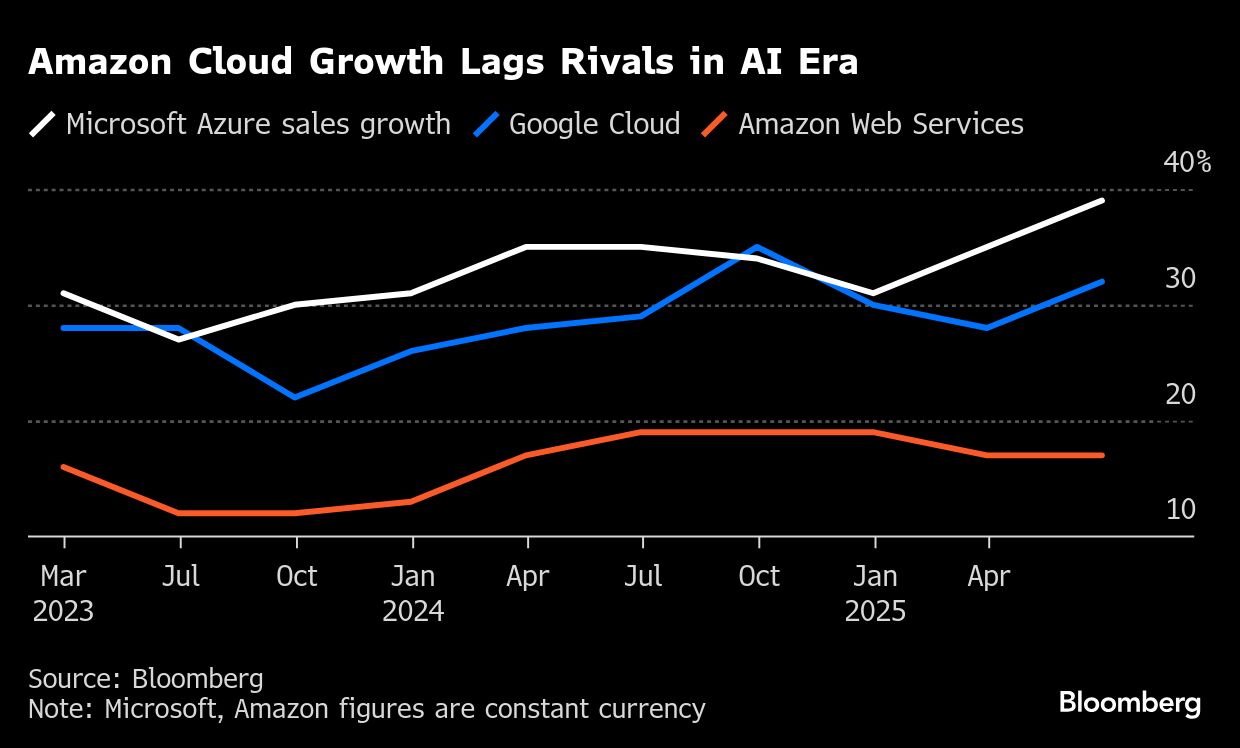
The breakdown occurred at a challenging moment for the Amazon Web Services cloud unit, which has long touted reliability and accountability as a core piece of its pitch to customers. Sales growth has slowed, and AWS has struggled to keep up as its two biggest rivals, Microsoft Corp. and Alphabet Inc.'s Google, grab new business selling artificial intelligence tools.
AWS remains the world's largest cloud provider and is hardly the first to suffer an outage. Moreover, it's not easy for customers to jump ship, especially given the current capacity crunch at data centers. Still, in recent years, some companies have sought to reduce their reliance on a single cloud provider.
“The outage will likely fuel customers wanting to spread their infrastructure between multiple clouds, which could be a positive for smaller vendors like Google,” said Bloomberg Intelligence analyst Anurag Rana. Still, he said, it's unlikely to result in any meaningful market share loss for Amazon due to the difficulty of shifting work between clouds and industrywide capacity constraints.
The promise cloud providers make to customers is essentially, “‘Don't worry, you don't have to operate infrastructure, you'll always have access to compute and storage,'” said D.A. Davidson analyst Gil Luria. “If you can't deliver that, that will stick in the mind of their customers.”
But switching is very expensive for customers, Luria said. “They'd have to be really upset, or significant damage has to be done for them to move,” he said. “For the incremental customer, is this the last straw for moving if they were already thinking of doing so? Maybe.”
Luria said the outage could make it harder for Amazon to attract new customers, especially startups. “Microsoft Azure and Google cloud services people are having a field day right now,” he said.
Amazon essentially invented the business of renting computing power at a large scale, stuffing data centers around the world with its own purpose-built hardware. AWS services, including data storage and database management, underpin a large chunk of the internet and account for about a third of the cloud market. So when bad things happen, chaos can spread quickly — as it did on Monday.
At first, it seemed as though Amazon had gotten a handle on the outage relatively quickly. The company said it discovered a malfunction in a digital directory for a key database service. That caused cascading failures when software reliant on the data trove was unable to retrieve information.
By early Monday New York time, the company said it had identified and fixed the underlying issue, which hit its operations in northern Virginia, where AWS operates its largest cluster of data centers.

But as the company worked to fix that issue, engineers found that other subsystems — including one necessary for customers to launch new rented servers — had been hit by the database outage. Before long, hundreds of companies and apps were reporting problems.
At the height of the outage, Downdetector tracked disruptions at hundreds of sites, including for financial services outfits Venmo and Robinhood Markets Inc., Apple's music and TV offerings, software companies such as Zoom Communications Inc., Salesforce Inc. and Snowflake Inc., and food-services giants including Wendy's Co. and McDonald's.
Even Amazon's own services, including Alexa and the Ring home security system, weren't immune.
For hours, AWS released jargon-heavy updates on its service health dashboard, assuring customers that the recovery process was underway. Finally, Amazon said all of its cloud services had “returned to normal operations” as of about 6 p.m. New York time — some 15 hours after the outage began.
It also took Amazon several hours to mitigate an outage in 2021 that affected everything from Disney amusement parks and Netflix videos to robot vacuums and Adele ticket sales. A smaller failure hit the cloud provider later that month.
Essential Business Intelligence, Continuous LIVE TV, Sharp Market Insights, Practical Personal Finance Advice and Latest Stories — On NDTV Profit.